
西野カナ風な歌詞自動生成「カナかな?」をリリースしてみた。
お疲れ様です。高橋です。
昨日はずっと助詞に関する実装をしていたのですが、どうしてもうまくいきませんでした。最終的にはなんとか解決し、本物の歌詞に於ける単語出現率は完全シミュレート出来たのですが、日本語的にはまだまだおかしな所だらけです。

処理が上手く行かなかった箇所で、最初はHashMapという型のせいかと疑いましたが、全然そんな事はありませんでした。
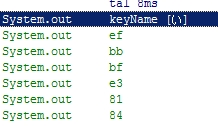
変換用文字列をテキストファイルにUTF-8で格納しておいて、それを読み込んでゴニョゴニョしていたんですが、取り込んだ後の物をバイナリレベルで見ると、「い」という文字が「EF BB BF E3 81 84」と、6バイト消費している事がわかりました。
UTF-8は普通3byteなので、先頭にゴミが付いていたのです。
じゃあ、この「EF BB BF」ってなんぞ?と思ってググると、
バイト順マークの使用について
UTF-8で符号されたテキストデータはエンディアンに関わらず同じ内容になるので、バイト順マーク (BOM) は必要ない。しかし、テキストデータがUTF-8で符号化されていることの標識として、データの先頭にEF BB BF(16進。UCSでのバイト順マークU+FEFFのUTF-8での表現)を付加することが許される。一部のテキスト処理アプリケーション(エディタなど)がこのような動作をする(TeraPad、EmEditorエディタのように付加するかどうかを選択できるものもある)。
という事でした。
最初はHashMapのSynchronize系を疑っていたのですが、私が使っていたテキストエディタがゴミを先頭文字に付加していたようです。JAVA神(じゃばがみ)様、疑って大変申し訳ございませんでした。
という事で大きな問題を解決する事が出来たので、Twitter連携とLINE連携を10分で実装し、Google Playに公開しました。
Google Playへのアプリ公開の一連の手順を早く踏んでみたかったのもあります。
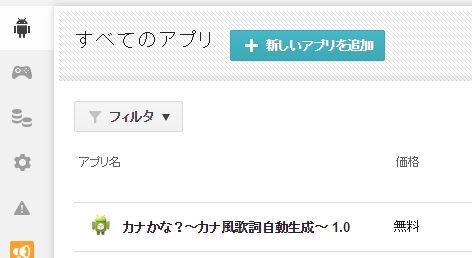
Google Playにアップロードする時に、様々なタイプの画像を準備しないといけないのですが、これがなかなかの量で、想定外の作業でした。アイコンや、検索時に表示される画像、バナー、スクリーンショットをスマホ版、タブレット版、などなど。非常に面倒だったので、こんな感じで漢らしく行きました。
![]()
リリース初週のダウンロード数は20程度行けばいいかな、と思っています。なんとなく20行けば良いレベルだと感じたからです。
Twitterを使った意図的な拡散は、もう少し日本語の精度を高めてから行おうと思います。
一番の問題は、アプリケーションの品質やアイコンや宣伝バナーのクリエイティブなんかより、実機で一度も試験していない、というか、実機を持っていない事なので、その問題に比べれば全て瑣末な事なのです。
明日はAndroidを持っている会社の人に人身御供になってもらいます。特にTwitterとLINEの自動連携部分が気になっています。
以上、よろしくお願い致します。
関連記事
-
-
アプリ開発に必要な要素技術
お疲れ様です。高橋です。 androidアプリ開発に必要な要素技術はものすごーー …
-
-
遅刻の言い訳アプリ ~ボタンの幅を動的に決定~
お疲れ様です。高橋です。 遅刻の言い訳アプリを着々と実装しています。 全体進捗 …
-
-
寝坊検知&遅刻の言い訳提案システム #2
お疲れ様です。高橋です。 昨日作った遅刻の言い訳提案システムですが、Tweetの …
-

-
遅刻の言い訳提案システムとウコンの力
お疲れ様です。高橋です。 現在稼働を続けている遅刻の言い訳提案システムは、改めて …
-

-
街頭インタビュー 実機デバッグ結果
お疲れ様です。高橋です。 先日リリースした街頭インタビューアプリの実機デバッグ、 …
-
-
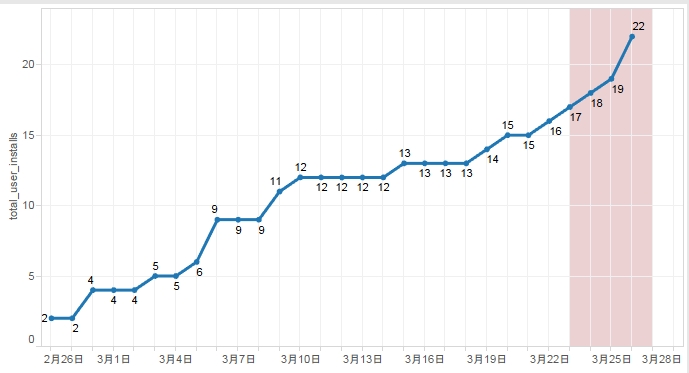
DLリンク付き言い訳提案システムとDL数の関係について
お疲れ様です。高橋です。 DLリンク付きの言い訳提案システムを1週間稼働させ、そ …
-

-
Unityでノベルゲームを作る
お疲れ様です。高橋です。 突然ですが、ノベルゲームを作ってみたくなったので、試し …
-

-
遅刻の言い訳アプリをリリースしてみた。
お疲れ様です。高橋です。 2/20あたりから、「合理的な遅刻の言い訳生成アプリ。 …
-

-
上司離着席状態検知アプリ
お疲れ様です。高橋です。 上司離着席状態検知システムですが、 必要性を記載 回路 …
-
-
「寝坊した」人に自動的に遅刻の言い訳を提案する仕組みを稼働させてみた。
お疲れ様です。高橋です。 寝坊した人にアプリをオススメする仕組みを作りましたが、 …